AI软件
Story-Adapter故事转图 嫁接文生图长故事生成器下载
- 2026-01-23
- 豆豆
- AI吧
Story-Adapter是一个专门用来把长篇文字故事,自动转换成一系列连贯图片的AI工具。你可以把它想象成一个“AI连环画生成器”。
Story-Adapter来源于一篇发表于2024年10月的计算机视觉学术研究。该研究由加州大学圣克鲁斯分校的研究团队提出,相关论文和技术细节公开在arXiv上,并且项目代码已在GitHub上开源,供公众学习和使用。
希望这份介绍能帮助你全面了解Story-Adapter。如果你对它的具体使用步骤、硬件要求或者其他类似的故事可视化工具感兴趣,我可以为你提供更多信息。
直接用现有的AI文生图模型(比如Stable Diffusion)来画长故事,会遇到几个大麻烦:故事里同一个角色在前后几张图里样子会变(语义不一致)、角色之间的互动细节画不好、而且生成很多张图电脑算起来也很吃力。
Story-Adapter就是为了解决这些问题而生的。它特别擅长处理长达100帧(张) 的复杂故事,能让整个故事里的角色样貌、场景风格都保持一致,并且画出更细腻的互动。
关键技术,像画家一样迭代精修。
它的工作原理很巧妙,不是一次性生成所有图,而是像画家创作长卷一样,采取“草稿-精修”的迭代流程:打草稿,先根据故事的每段文字提示,生成第一版所有图片。
回头看与精修,在生成下一轮图片时,它不仅看当前的文字描述,还会同时参考前一轮生成的所有图片。通过一个叫 “全局参考交叉注意力(GRCA)” 的核心模块,系统能记住前面图片里的角色长相、环境色调等信息,并把这些信息融入新图的生成中。
多轮优化:这个过程会重复好几轮。每一轮,图片的连贯性和细节都会变得更好,错误也被逐步修正。
开箱即用,无需训练,它本身不是一个新模型,而是一个可以“嫁接”在现有文生图模型(如Stable Diffusion)上的框架。用户不需要自己费力重新训练AI模型,直接使用即可,门槛较低。
保持高度一致性:通过上述迭代和全局参考机制,能有效确保长故事中角色和场景的前后统一。
兼顾效率:GRCA模块通过使用浓缩的图像特征(全局嵌入)来传递信息,而不是处理所有原始图片数据,从而控制了计算成本。
软件图片:
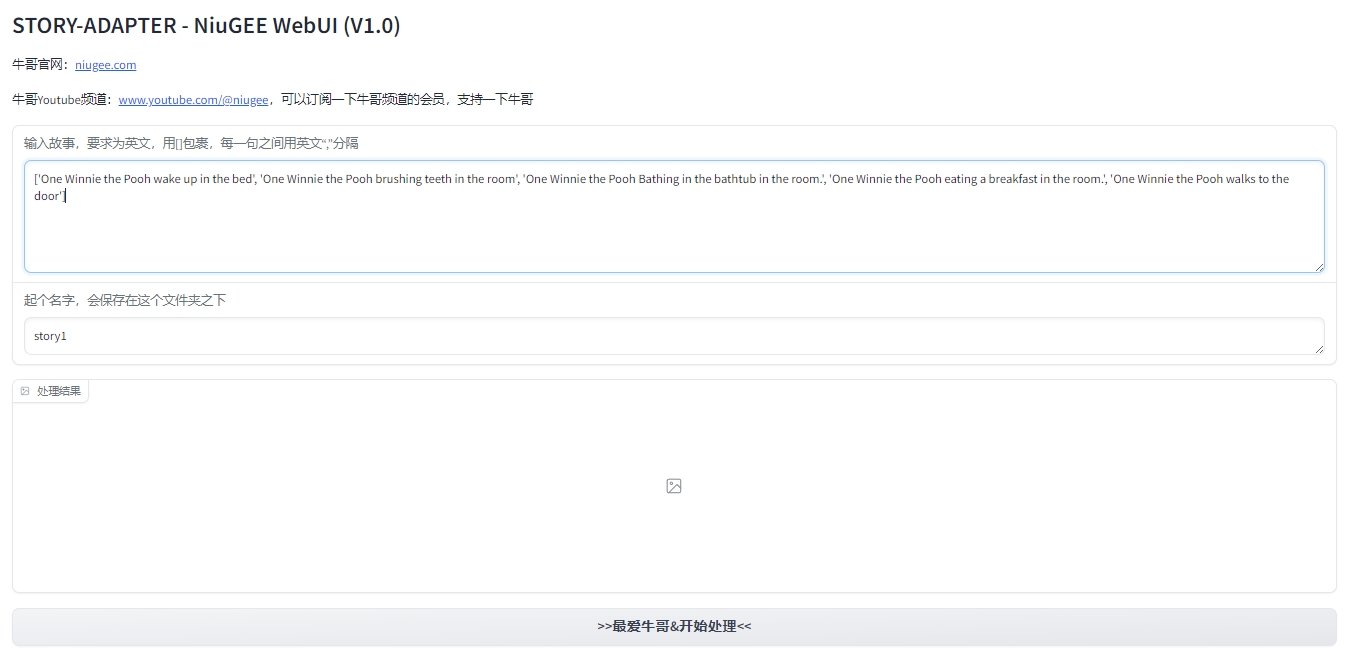
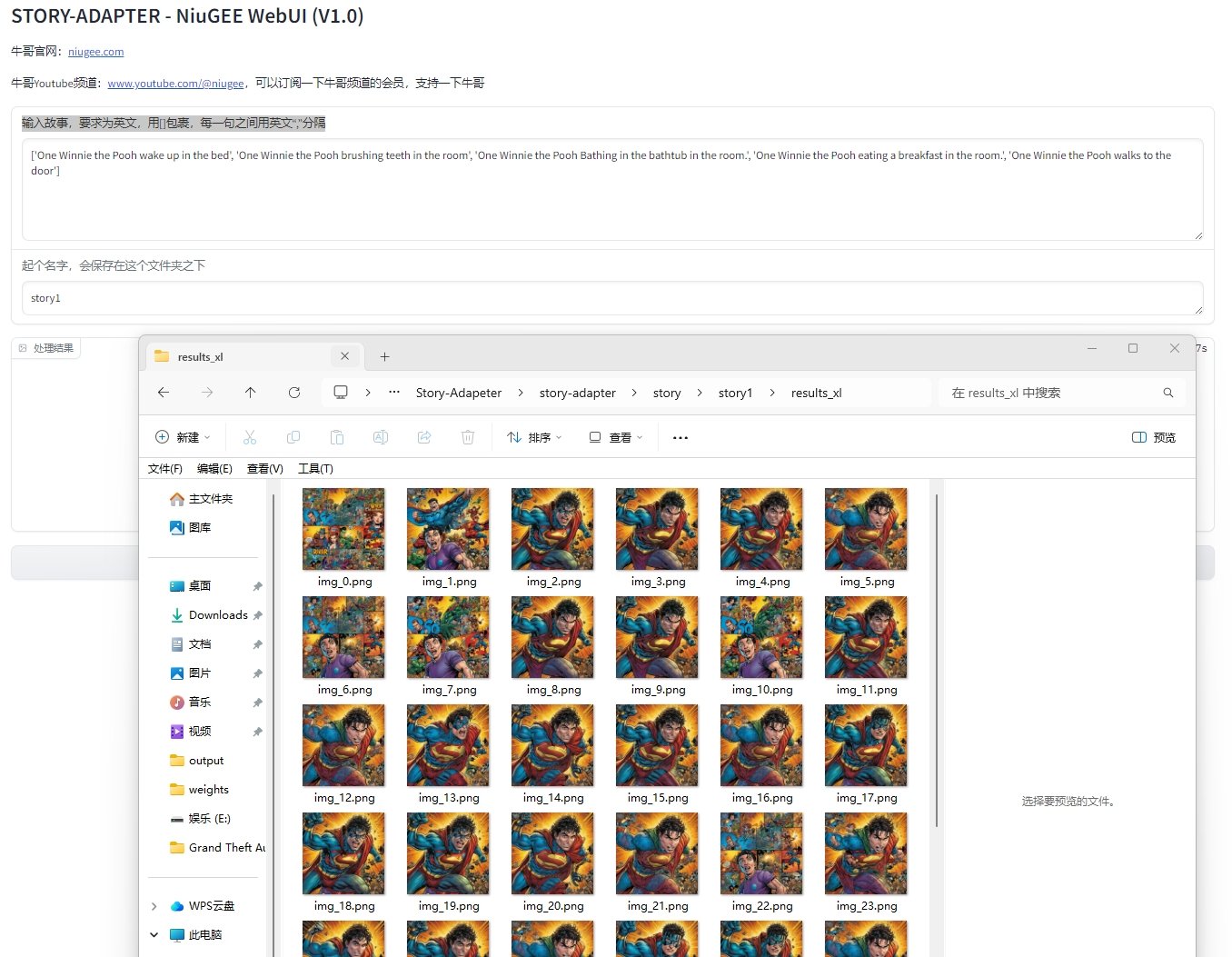
软件信息:
容量大小:45G
操作页面:webui