AI硬件
gaudi2加速卡吊打H100 英特尔推出王炸产品
- 2023-07-14
- 机器之心
- 网络
越是强大的AI模型就越需要算力,这已经成了AI的业界共识。就拿ChatGPT举个例子,它在训练的时候可是用到了约2.5万块A100,训练时长超90天。
那各家公司又是靠什么来支撑如此庞大的算力的呢?答案是GPU。大部分的制作者都在依赖AI加速卡进行维持高强度的算力,但这也并不是长久之计。但幸运的是,最近英特尔面向国内提出了一个全新的解决方案,比之前的方法更省力也更安全。
7 月 11 日在北京举行的发布会上,英特尔正式于中国市场推出第二代 Gaudi 深度学习加速器 ——Habana Gaudi2。

昨天的活动中,英特尔介绍了 Gaudi2 芯片的性能,并讨论了面向中国市场的英特尔 AI 战略、最新 AI 相关产品技术进展和解决方案的应用。
「Gaudi 深度学习加速器的大语言模型训练能力进一步丰富了我们的人工智能产品阵列,」英特尔公司执行副总裁、数据中心与人工智能事业部总经理 Sandra Rivera 表示。「对于在中国运行深度学习训练和推理工作负载的客户来说,与市场上其他面向大规模生成式 AI 和大语言模型的产品相比,Gaudi2 是更理想的选择。除了在性能表现上超过 A100 之外,Gaudi2 在各种最先进的模型上相对于 A100 提供了约两倍的性价比。」

上周,英特尔 Habana Gaudi2 深度学习加速器和第四代英特尔至强可扩展处理器在 MLPerf Training 3.0 基准测试的最新榜单上展示了令人印象深刻的结果。该基准由 MLCommons 发布,是业内广泛认可的 AI 性能行业标准。
Gaudi2 加速器在计算机视觉模型 ResNet-50(8 卡)、Unet3D(8 卡),以及自然语言处理模型 BERT(8/64 卡)上均取得了优异的训练结果,在每个模型上性能都优于 A100,部分任务上接近 H100。
此外,在大语言模型 GPT-3 的评测上,Gaudi2 也展现了实力。它是仅有的两个提交了 GPT-3 LLM 训练性能结果的解决方案之一(另一个是英伟达 H100)。在 GPT-3 的训练上,英特尔使用 384 块 Gaudi 2 加速器使用 311 分钟训练完成,在 GPT-3 模型上从 256 个加速器到 384 个加速器实现了近线性 95% 的扩展。
「相比之下,英伟达在 512 块 H100 GPU 上的训练时间则为 64 分钟。这意味着,基于 GPT-3 模型,每个 H100 的性能领先于 Gaudi2 3.6 倍,」Habana Labs 首席运营官 Eitan Medina 表示。「性价比是影响 H100 和 Gaudi2 相对价值的重要考量因素。Gaudi2 服务器的成本要比 H100 低得多。即使还没有配备 FP8,Gaudi2 在性价比上也胜过了 H100。」
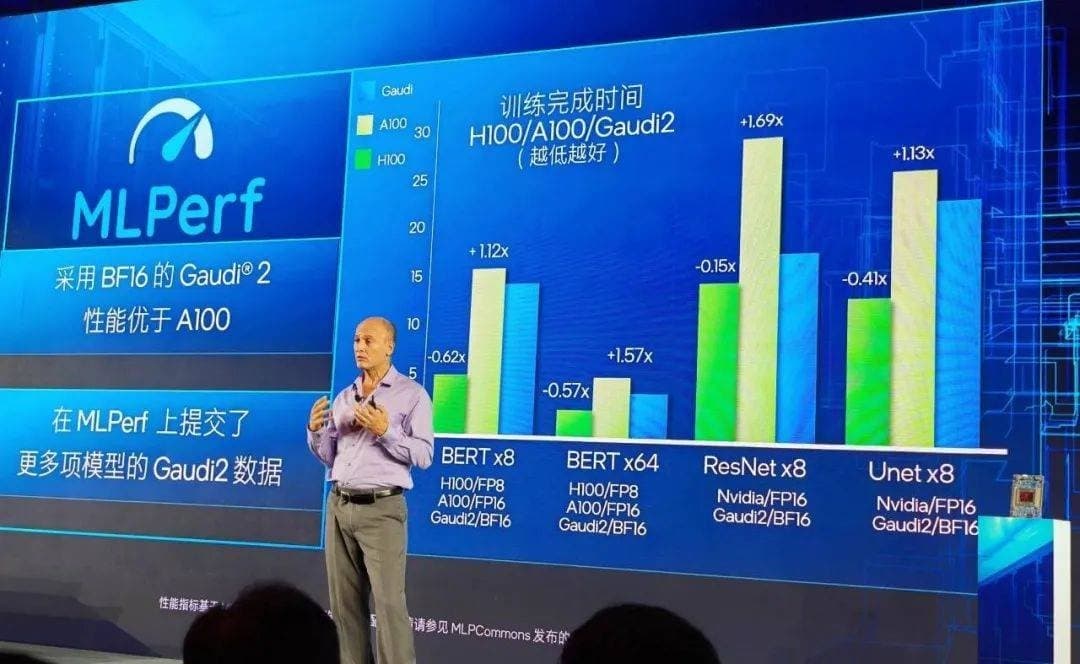
英特尔表示,Gaudi2 在 MLPerf 上提交的结果没有经过模型或框架的特殊调校,这意味着用户也可以在本地或云端部署 Gaudi2 时获得类似的性能结果。
Gaudi2 在服务器和系统成本方面还具有显著的成本优势,这使得它可以成为英伟达 H100 的有力竞争对手。
去年,英特尔旗下的 Habana Labs 推出了第二代 AI 训练加推理芯片 Gaudi2。与头一代产品相比,Habana Gaudi 2 使用的制程工艺从 16 纳米跃升至 7 纳米,在矩阵乘法(MME)和 Tensor 处理器核心计算引擎中引入了 FP8 在内的新数据类型,Tensor 处理器核心数量增至 24 个,同时集成了多媒体处理引擎,内存升级至 96GB HBM2E。

在当前生成式 AI 看重的扩展性能方面,国内版本的 Gaudi2 每张芯片集成了 21 个专用于内部互联的 100Gbps(RoCEv2 RDMA)以太网接口(相比海外版本略有减少),从而实现了低延迟的服务器内扩展。
为支持客户轻松构建模型,或将当前基于 GPU 的应用迁移到 Gaudi2 服务器上,英特尔提供的 SynapseAI 软件套件针对 Gaudi 平台深度学习业务进行了优化。SynapseAI 集成了对 TensorFlow 和 PyTorch 框架的支持,并提供众多流行的计算机视觉和自然语言参考模型,能够满足深度学习开发者的多样化需求。
而在 Hugging Face 平台上,已有超过 5 万个模型使用 Optimum Habana 软件库进行了优化。Sandra Rivera 表示,英特尔通过与 Hugging Face 的合作,平台上的现有的模型只需要花费几十秒时间就可以调通运行在 Gaudi 加速器上。
目前,已有 OEM 厂商推出了基于英特尔 AI 加速卡的产品。在发布活动中,英特尔宣布 Gaudi2 首先将通过浪潮信息向国内客户提供,其服务器集成了 8 块 Gaudi2 加速卡 HL-225B,还包含两颗第四代英特尔至强可扩展处理器。
昨天的活动上,英特尔分享了他们在AI加速领域未来的发展战略。据悉,Gaudi 3芯片将于明年推出,并采用台积电5纳米制程技术生产。同时,英特尔还将同步推出国内版。预计到2025年,英特尔计划将Gaudi芯片整合到现有的GPU产品线中。这一计划的实施将有望进一步提升英特尔在AI领域的竞争力和市场份额。
且该芯片在采用了台积电5纳米制程技术生产后,具有较高的性能和效率。Gaudi芯片在性能方面的实力可以说是毋庸置疑的,如果Gaudi芯片能够成功推广并得到广泛应用,将有助于英特尔进一步提高在AI领域的实力,从而巩固其在半导体行业的领导地位。
那各家公司又是靠什么来支撑如此庞大的算力的呢?答案是GPU。大部分的制作者都在依赖AI加速卡进行维持高强度的算力,但这也并不是长久之计。但幸运的是,最近英特尔面向国内提出了一个全新的解决方案,比之前的方法更省力也更安全。
7 月 11 日在北京举行的发布会上,英特尔正式于中国市场推出第二代 Gaudi 深度学习加速器 ——Habana Gaudi2。
昨天的活动中,英特尔介绍了 Gaudi2 芯片的性能,并讨论了面向中国市场的英特尔 AI 战略、最新 AI 相关产品技术进展和解决方案的应用。
「Gaudi 深度学习加速器的大语言模型训练能力进一步丰富了我们的人工智能产品阵列,」英特尔公司执行副总裁、数据中心与人工智能事业部总经理 Sandra Rivera 表示。「对于在中国运行深度学习训练和推理工作负载的客户来说,与市场上其他面向大规模生成式 AI 和大语言模型的产品相比,Gaudi2 是更理想的选择。除了在性能表现上超过 A100 之外,Gaudi2 在各种最先进的模型上相对于 A100 提供了约两倍的性价比。」
上周,英特尔 Habana Gaudi2 深度学习加速器和第四代英特尔至强可扩展处理器在 MLPerf Training 3.0 基准测试的最新榜单上展示了令人印象深刻的结果。该基准由 MLCommons 发布,是业内广泛认可的 AI 性能行业标准。
Gaudi2 加速器在计算机视觉模型 ResNet-50(8 卡)、Unet3D(8 卡),以及自然语言处理模型 BERT(8/64 卡)上均取得了优异的训练结果,在每个模型上性能都优于 A100,部分任务上接近 H100。
此外,在大语言模型 GPT-3 的评测上,Gaudi2 也展现了实力。它是仅有的两个提交了 GPT-3 LLM 训练性能结果的解决方案之一(另一个是英伟达 H100)。在 GPT-3 的训练上,英特尔使用 384 块 Gaudi 2 加速器使用 311 分钟训练完成,在 GPT-3 模型上从 256 个加速器到 384 个加速器实现了近线性 95% 的扩展。
「相比之下,英伟达在 512 块 H100 GPU 上的训练时间则为 64 分钟。这意味着,基于 GPT-3 模型,每个 H100 的性能领先于 Gaudi2 3.6 倍,」Habana Labs 首席运营官 Eitan Medina 表示。「性价比是影响 H100 和 Gaudi2 相对价值的重要考量因素。Gaudi2 服务器的成本要比 H100 低得多。即使还没有配备 FP8,Gaudi2 在性价比上也胜过了 H100。」
英特尔表示,Gaudi2 在 MLPerf 上提交的结果没有经过模型或框架的特殊调校,这意味着用户也可以在本地或云端部署 Gaudi2 时获得类似的性能结果。
Gaudi2 在服务器和系统成本方面还具有显著的成本优势,这使得它可以成为英伟达 H100 的有力竞争对手。
去年,英特尔旗下的 Habana Labs 推出了第二代 AI 训练加推理芯片 Gaudi2。与头一代产品相比,Habana Gaudi 2 使用的制程工艺从 16 纳米跃升至 7 纳米,在矩阵乘法(MME)和 Tensor 处理器核心计算引擎中引入了 FP8 在内的新数据类型,Tensor 处理器核心数量增至 24 个,同时集成了多媒体处理引擎,内存升级至 96GB HBM2E。
在当前生成式 AI 看重的扩展性能方面,国内版本的 Gaudi2 每张芯片集成了 21 个专用于内部互联的 100Gbps(RoCEv2 RDMA)以太网接口(相比海外版本略有减少),从而实现了低延迟的服务器内扩展。
为支持客户轻松构建模型,或将当前基于 GPU 的应用迁移到 Gaudi2 服务器上,英特尔提供的 SynapseAI 软件套件针对 Gaudi 平台深度学习业务进行了优化。SynapseAI 集成了对 TensorFlow 和 PyTorch 框架的支持,并提供众多流行的计算机视觉和自然语言参考模型,能够满足深度学习开发者的多样化需求。
而在 Hugging Face 平台上,已有超过 5 万个模型使用 Optimum Habana 软件库进行了优化。Sandra Rivera 表示,英特尔通过与 Hugging Face 的合作,平台上的现有的模型只需要花费几十秒时间就可以调通运行在 Gaudi 加速器上。
目前,已有 OEM 厂商推出了基于英特尔 AI 加速卡的产品。在发布活动中,英特尔宣布 Gaudi2 首先将通过浪潮信息向国内客户提供,其服务器集成了 8 块 Gaudi2 加速卡 HL-225B,还包含两颗第四代英特尔至强可扩展处理器。
昨天的活动上,英特尔分享了他们在AI加速领域未来的发展战略。据悉,Gaudi 3芯片将于明年推出,并采用台积电5纳米制程技术生产。同时,英特尔还将同步推出国内版。预计到2025年,英特尔计划将Gaudi芯片整合到现有的GPU产品线中。这一计划的实施将有望进一步提升英特尔在AI领域的竞争力和市场份额。
且该芯片在采用了台积电5纳米制程技术生产后,具有较高的性能和效率。Gaudi芯片在性能方面的实力可以说是毋庸置疑的,如果Gaudi芯片能够成功推广并得到广泛应用,将有助于英特尔进一步提高在AI领域的实力,从而巩固其在半导体行业的领导地位。