AI软件
Voxcpm1.5声音克隆软件下载
- 2026-01-19
- 豆豆
- 未知
软件介绍:
核心能力:
高保真克隆:基于 44.1 kHz 高采样率,复现音色、韵律、语速等细节。
高效合成:约 6.25 token/秒 的计算开销,合成速度较前代翻倍。
上下文表达:根据文本语义与情感倾向,动态调整语调、停顿与语气。
定制支持:提供 LoRA 与全参微调流程,支持多层次个性化。
关键设计:
端到端生成:摒弃传统分词器,直接对原始文本建模,减少量化带来的信息损失。
混合机制:扩散负责去噪与细节,自回归保证时序连贯与可控性。
语义主干:集成 MiniCPM-4 作为语义网络,分层表征协同文本与声学特征。
训练策略:结合 FSQ 约束与流匹配,提升稳定性与一致性。
式合成:低延迟推理,在消费级 GPU(如 RTX 4090)可实现约 0.15 的实时因子,满足实时交互。
应用场景:
智能硬件交互:为音箱、车载与 IoT 设备提供自然、响应快的语音交互。
数字内容创作:批量将文本转为高品质音频,适用于有声书、播客、资讯朗读等。
语言学习:模拟特定发音与口音,生成沉浸式练习材料。
游戏与虚拟世界:为角色快速生成贴合剧情与情绪的配音。
品牌声音:复刻并统一品牌代言人或企业 IP 的声音形象,用于广告、客服与多媒体旁白。
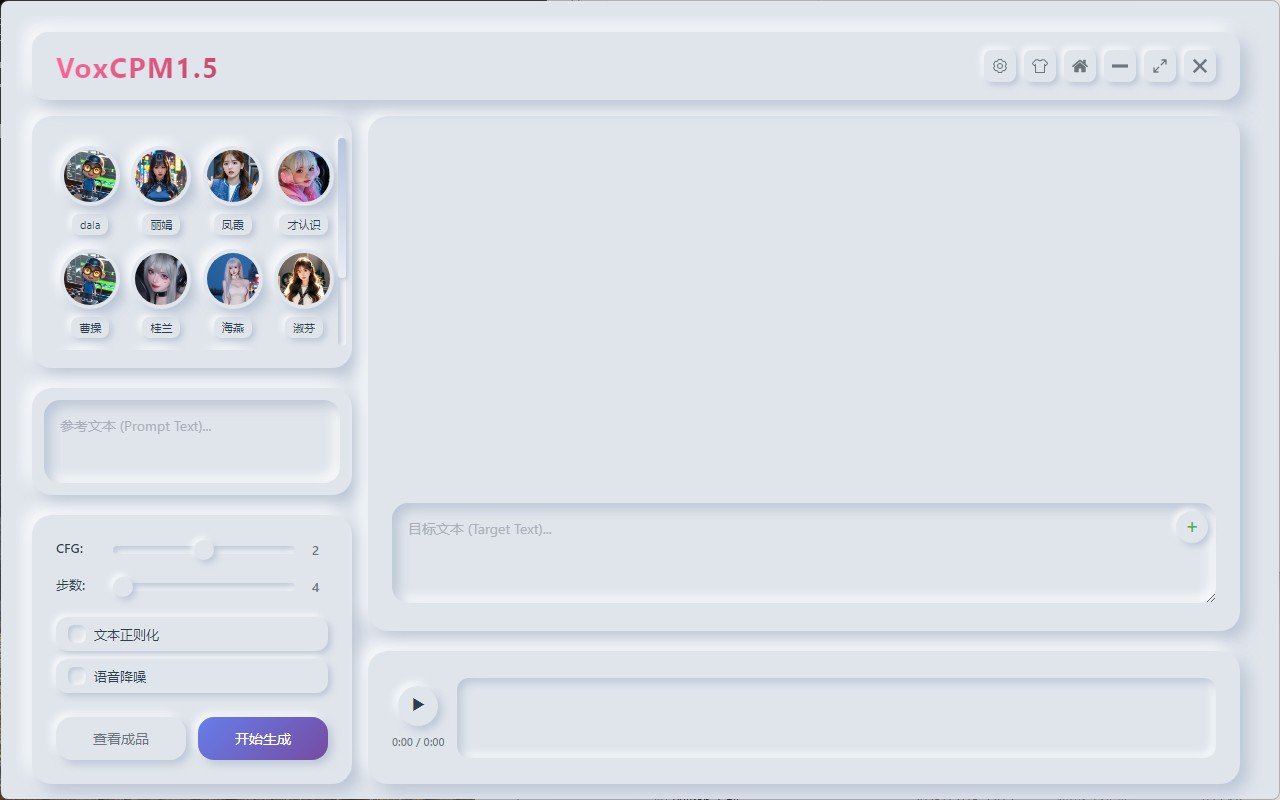
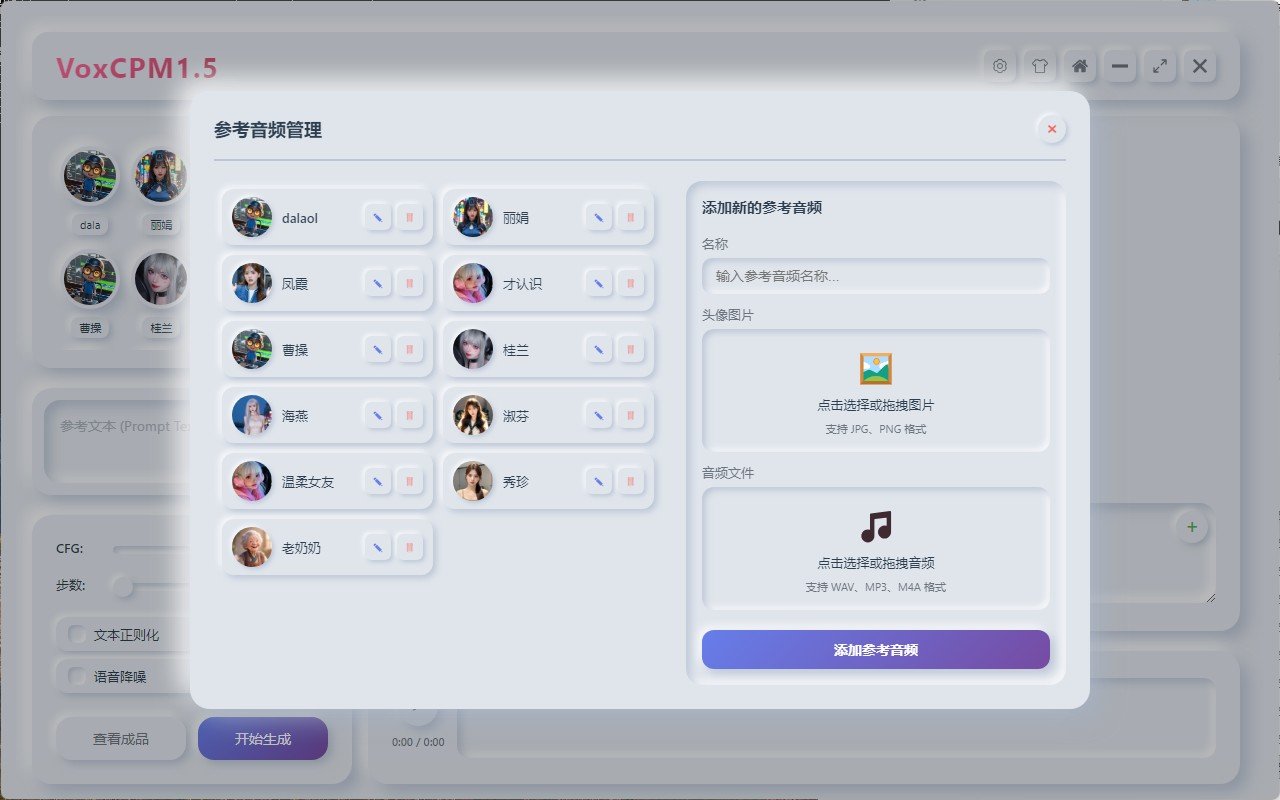
软件图片:
软件信息:
容量大小:10G
操作页面:exe软件